DIGITAL ELECTRONIC
In this article, we dive deep into the core concepts of multithreading. We will have a look at the profound understandings of the terms Concurrency and Parallelism with their description. Then, we compare the major differences between the two terms. Concurrency and Parallelism are often misunderstood to be somewhat similar but it is not the case when we consider it with aspects of Multithreading.
Concurrency
By Concurrency, we mean executing multiple tasks on the same core. In simpler terms, it relates to processing more than one task at the same time. It is a state in which multiple tasks start, run, and complete in overlapping time periods. An application capable of executing multiple tasks virtually at the same time is called a Concurrent application.
In case the computer only has one CPU or one Core the application may not make progress on more than one task at the exact same time. Instead, divide the time and the Core/CPU among various tasks. Concurrency is useful in decreasing the response time of the system.
Let us see this example and figure out the working of concurrent processes within a single core.
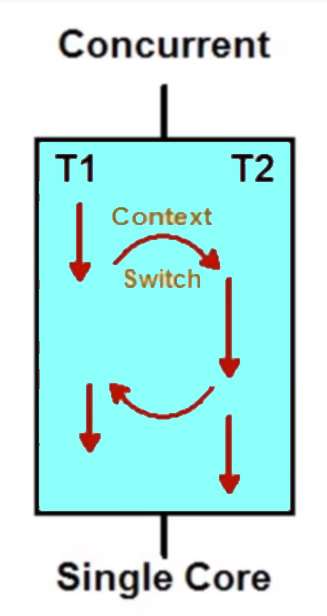
Here, we have two tasks T1 and T2 running on a single core. The task T1 is given a time slice for which it executes afterward the control of execution is given to T2 by the core this is called Context Switching, where a single core is shared among different processes or tasks effectively for small time slice to execute part of a process.
Parallelism
Parallelism is the ability of an application to split up its processes or tasks into smaller subtasks that are processed simultaneously or in parallel. It is the mechanism in which multiple processes execute independently of each other where each process acquires a separate core. This utilizes all the cores of the CPU or processor to run multiple tasks simultaneously.
Hence, to achieve parallelism the application must have more than one thread running on separate cores. In a single core CPU parallelism is not possible due to lack of hardware (Multi-Core Infrastructure). Parallelism is effective in improving the overall throughput resulting in faster execution. Let us look at an example:
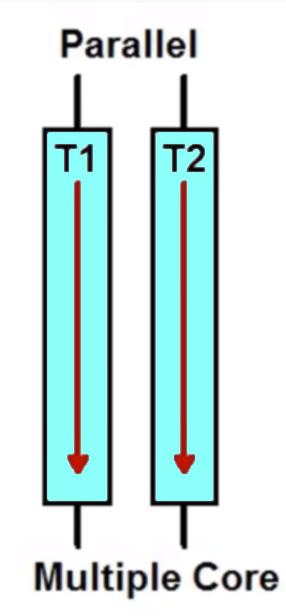
As you can see in the above figure, the two tasks T1 and T2 execute in parallel to each other. The two tasks run on separate cores and are independent of each other. This leads to faster execution because there is no time slice for the process. They do not have to wait for a process to finish and allocate CPU to other processes which were evident in the case of Concurrency.
Concurrency vs Parallelism
Now, we have a look at some key differences between Concurrency and Parallelism:
Concurrency |
Parallelism |
| 1. It is the mechanism to run multiple processes at the same time not necessary to be simultaneous. | 1. It is the ability to split a heavyweight process into smaller independent subtasks and run those simultaneously. |
| 2. Context Switching plays an important role in implementing concurrency. | 2. In Parallelism, the sub-processes run separately so there is no overhead of Context Switching. |
| 3. It is achieved using Single processing units or through a single core. | 3. It requires Multiple Processing Units as processes run separately on different cores. |
| 4. It runs on a single core so hardware is less required. | 4. The implementation requires multiple cores for each of the processes so hardware cost is comparatively more here. |
| 5. It increases the amount of work finished at a time and helps in decreasing response time considerably. | 5. It is responsible for increasing the throughput of the system and in faster execution. |
| 6. Concurrency is about dealing with a lot of things at once. | 6. However, parallelism is about doing a lot of things at the same instant. |
That’s it for the article, these core concepts are helpful in solving large scale problems. We looked into the description of each topic with their examples.
Feel free to leave your queries in the comment section below.
The post Concurrency vs Parallelism – Difference between Concurrency and Parallelism appeared first on The Crazy Programmer.
from The Crazy Programmer https://ift.tt/2Nzh6I4