DIGITAL ELECTRONIC
In this article, we will learn about 2-3-4 Trees. We will look at the creation of 2-3-4 trees and look at the operations performed on this trees with examples. We will also look at the time for each operation and its applications.
2-3-4 Tree is a Self-balancing, Multiway Search Tree. It is always perfectly balanced. 2-3-4 Trees are also known by name 2-4 Trees and is a specialization of M-way Tree (M=4). These sometimes also called as 4th order B-trees are useful in indexing and storage in large databases systems.
Properties
Now, let us look at some properties of 2-3-4 trees and its structure:
- Each Node in the tree can store at most 3 values/keys and 4 references or pointers to child nodes.
- The values in each node are Ordered or in Sorted form.
- All leaf nodes are at same level. Hence making it perfectly balanced.
- An Internal (non-leaf) node can either have 2, 3 or 4 children. To be more precise, nodes can be of the following three types.
- 2-Node: Node has two child pointers and 1 data or key value.
- 3-Node: Node has three child pointers and 2 data elements..
- 4-Node: Node has four child pointers and 3 data elements.
- A leaf node can have 2, 3 or 4 items but no children. In other words, a leaf is 2-Node, 3-Node or 4-Node where all pointers hold NULL reference.
Now let us look at the the type of nodes in 2-3-4 tree and structure of each node:
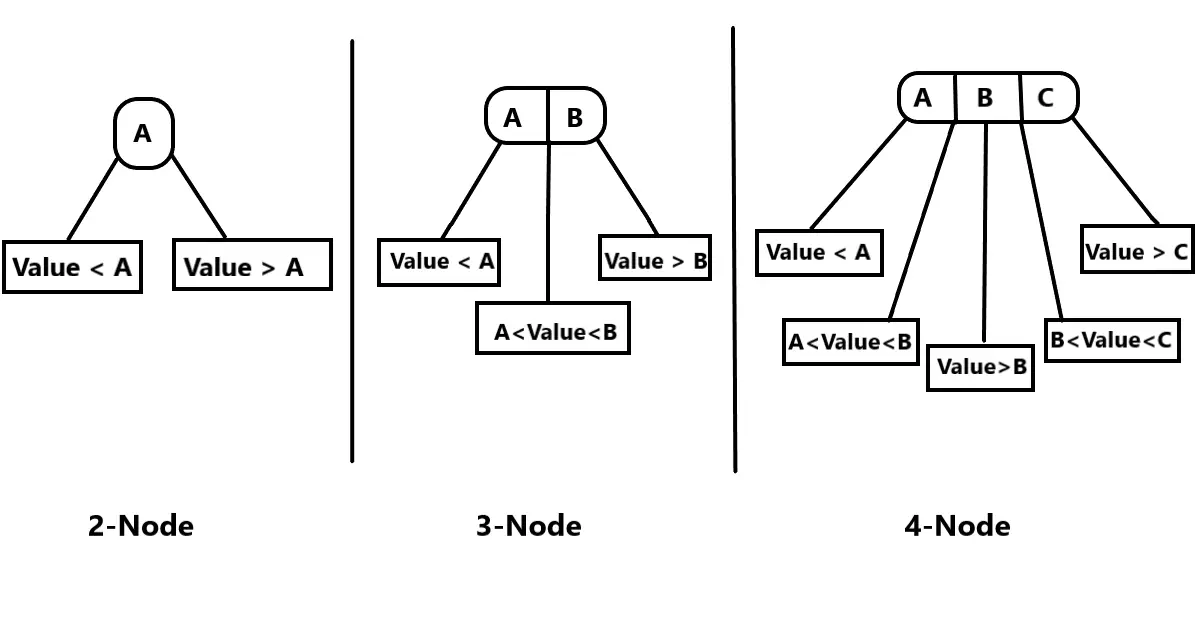
In the above examples, we have shown the Structure of 2-Node, 3-Node, and 4-Node. We can see the 2-Node consists of only one Data/Value (A) and has two pointers to its left and right children, where value of left child is smaller than the parent and value of right child is greater than the parent. In 3-Node there are 2 Values i.e. (A, B) and 3 pointers: The first pointer points to left child with Value smaller than A, the second pointer holds the node with a Value greater than A but lesser than B and the third pointer points to node with a value greater than B. Similarly, in 4-Node the node has 3 Values i.e. (A, B, C) and 4 child pointers as shown in the figure.
Creation of 2-3-4 Tree with Insertion
So, while creating a 2-3-4 tree and for inserting nodes we have to follow some rules:
- We insert each data item in the node in sorted order. A node can hold maximum 3 values i.e. 4 node.
- When we try inserting an element in a 4-Node we will split the node and move the middle item to its parent node if the parent becomes a 4-Node we split it again.
- Once a node is split we cannot insert value in the parent node, we need to traverse to its child nodes and then insert or split the node itself.
- Usually The Parent Node cannot be a 4-Node so we can accommodate the extra data inside it while inserting.
Let us understand with Step by Step example:
Suppose we are creating a 2-3-4 Tree with random data: [3,1,5,4,2,9,10]. We follow these steps:
Step 1:
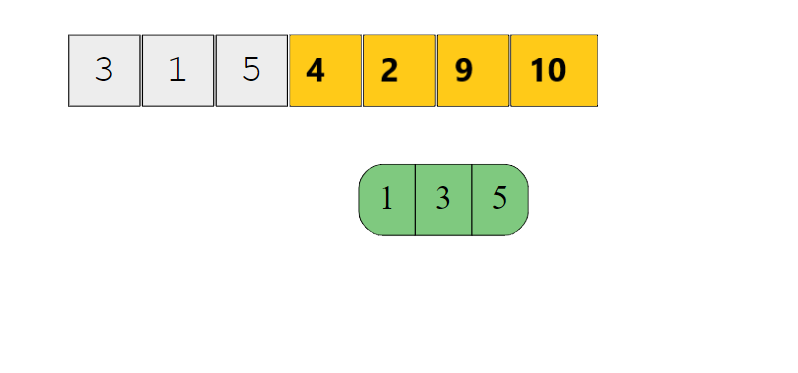
We insert value 3, 1, 5 serially maintaining the order in nodes while insertion. We insert values or data items in node until it becomes a 4-node. After inserting the values the node becomes a 4-Node. 3 gets inserted first, 1 is smaller so is inserted before 3 and 5 being largest is inserted after 3.
Step 2:
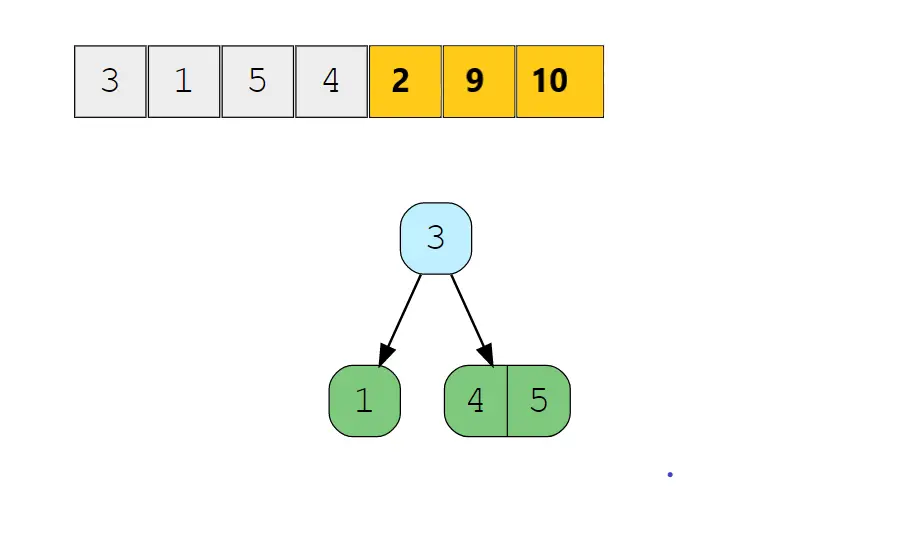
Now, when we try inserting 4, there is no space to insert it so we have to split the node from the middle element (3). Now 3 becomes the parent node (Root) and has left child node 1 and in right child 5, as value 4 is greater than 3 we insert it in its right child with node 5 in sorted order. The tree remains balanced and looks like:
Step 3:
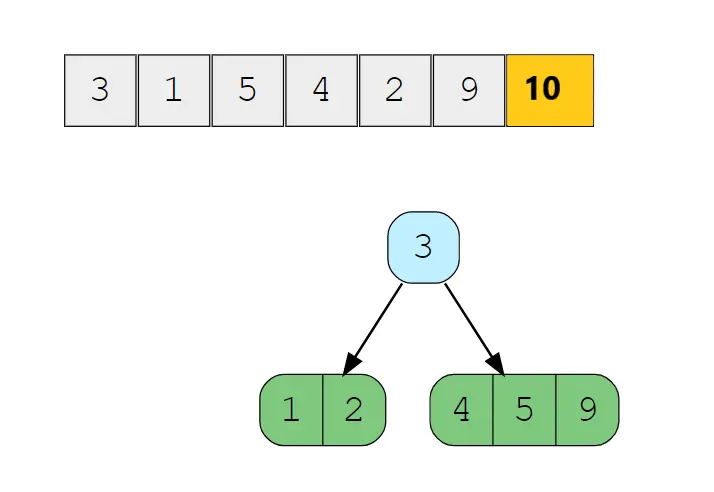
Now, when we insert value 2 into the tree we traverse down comparing value with Present Root 3,we insert value 2 into its left child as it is a 2-Node so we insert after 1. Now when we insert 9 we check again with the root 3 , since the value is greater we traverse down to its right child and then insert in it maintaining the order as the right child is 3-Node and has space to accommodate one more node. The 2-3-4 Tree now looks:
Step 4:
Finally, we try to insert 10 as it is greater than 3 so we go to its right child but the node is already a 4-Node, so we split the node from the middle element again and send node 5 to the parent node as it has space to accommodate (Discussed in Rules) now parent node has values 3 and 5 in it since 4 is less than 5 so it becomes the left child of 5 and right child of 3. Now we can insert 10 in the right child of 5 after 9. So, The 2-3-4 tree now looks like:
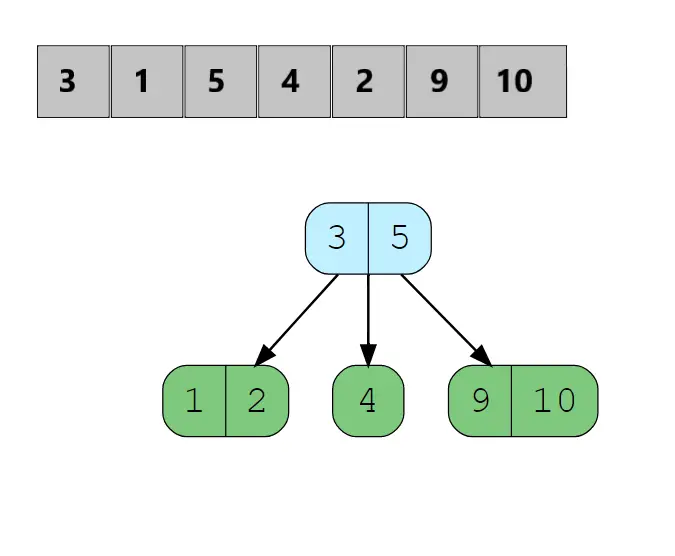
Deletion in 2-3-4 Tree
Deletion in 2-3-4 Tree is a complex operation. When we delete items from a tree instead of splitting nodes in Insertion, we will merge them recursively on the way we traverse down. We merge nodes while traversing if their child nodes have less than 2 keys. The Deletion operation can be narrowed down to 3 cases:
Case 1
Element is a Leaf Node with At least 2 Key/Values: If the element to delete in a node is a leaf node and has at least 2 Values in it then we can delete it straight forward. This is an edge case.
Case 2
Element is an Internal Node: If the element to delete is in a Node that is non-leaf or Internal there are again three possible conditions:
- If Left Child has 2 Keys then replace the element with its predecessor or value in the left child and then delete it.
- Or, If the Right Child has 2 keys then replace it with its successor and then delete it.
- Now, If Both Left Child and Right Child have 1 key then merge them to form a balanced node and then delete the element.
Case 3
Element is not an Internal Node: If the element to delete is in a node which is a Leaf Node or Non Internal Node then there are again two possibilities.
- If the Node has 1 key then we check its siblings or neighbor nodes if the Sibling has at least 2 keys. Then, we Rotate elements into the parent node and move the element in the parent node to the next node child node then delete it.
- If Node has 1 key and both child nodes are siblings with 1 key each then merge the two children and the parent element into the node then delete it.
Let us also understand this with a step by step example:
Consider this 2-3-4 tree:
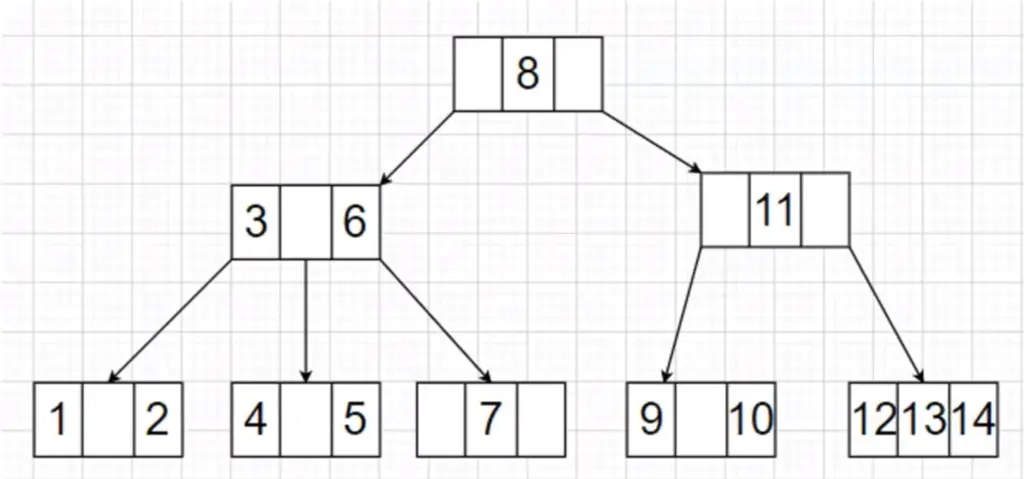
We will perform delete operation in the given sequence: 1, 7, 6, 9, 3, 8. The steps are shown below:
Step 1:
To delete element 1 we traverse down to the node containing the value, it falls under Case 1 since the node is a leaf node and has at least two keys so we delete it. The 2-3-4 tree now is:
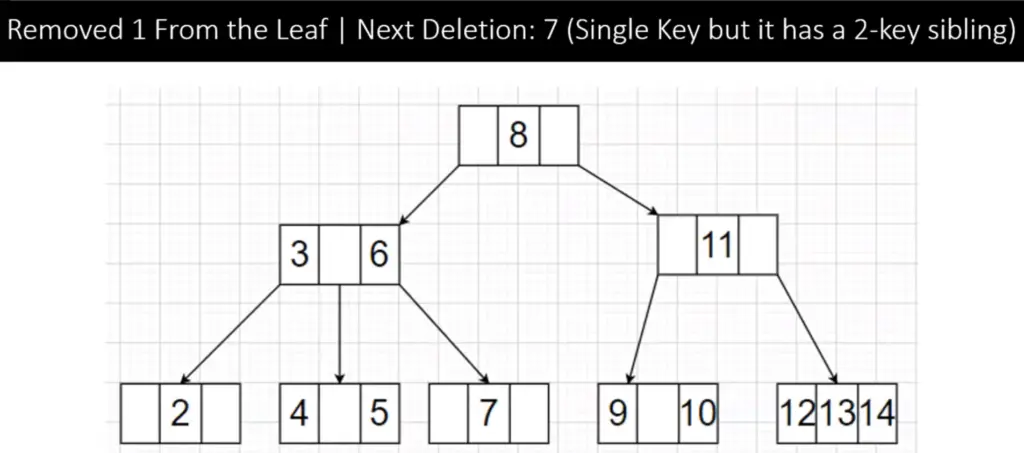
Step 2:
To delete 7, we see it is a leaf node with 1 key so we check its siblings which have two keys (4 and 5) this falls under Case 3 Type 2. So we rotate elements by one from the sibling to parent to the node then delete 7. The tree after rotation and deletion is shown below:
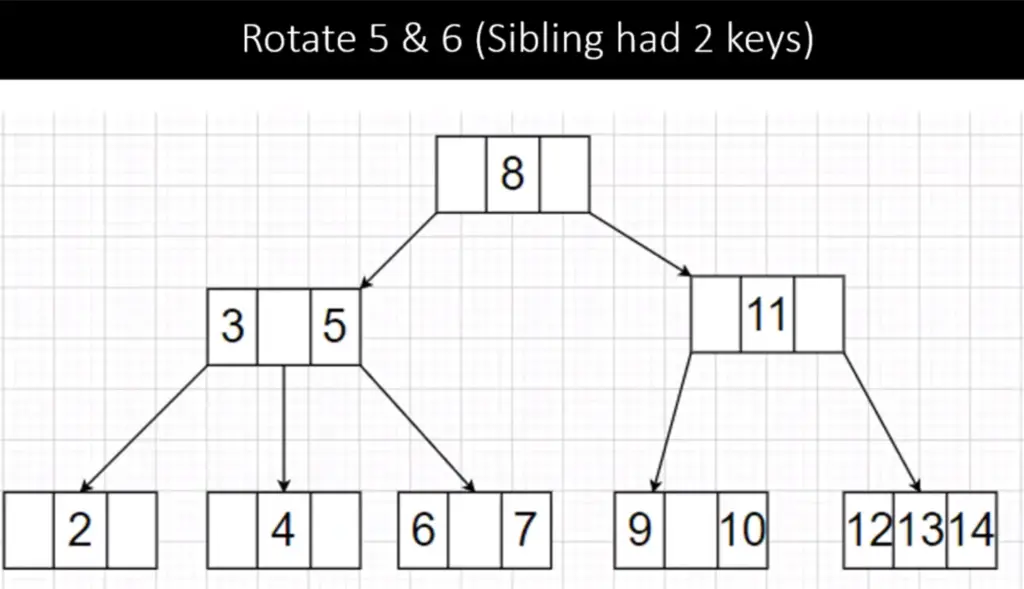
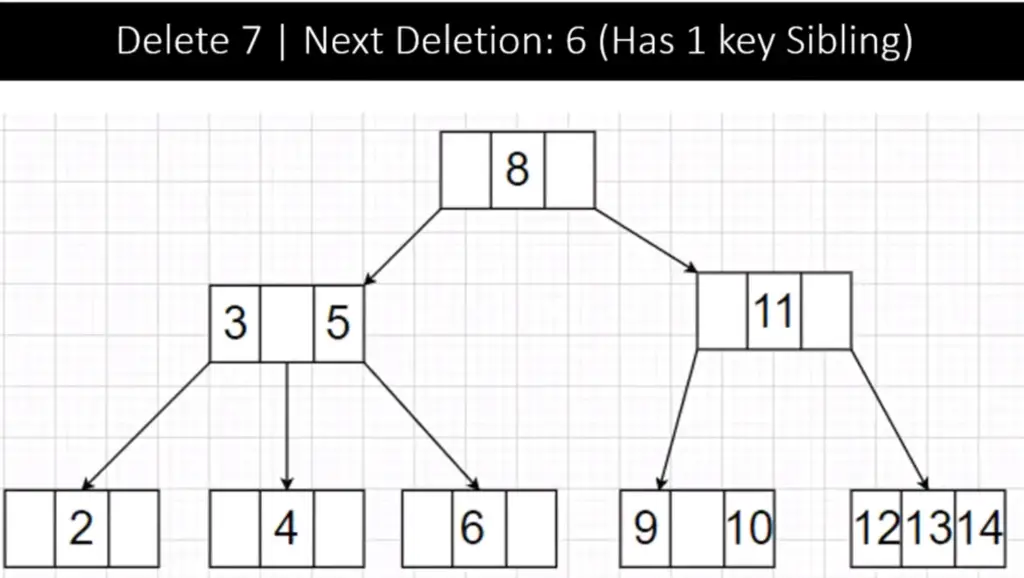
Step 3:
To delete 6, we see the node has 1 key so we check its siblings which also has 1 key, this falls under Case 3 Type 1 so we merge the two nodes with the parent to form a balanced node(4,5 and 6) with 3 keys (4-Node). The tree now looks like:
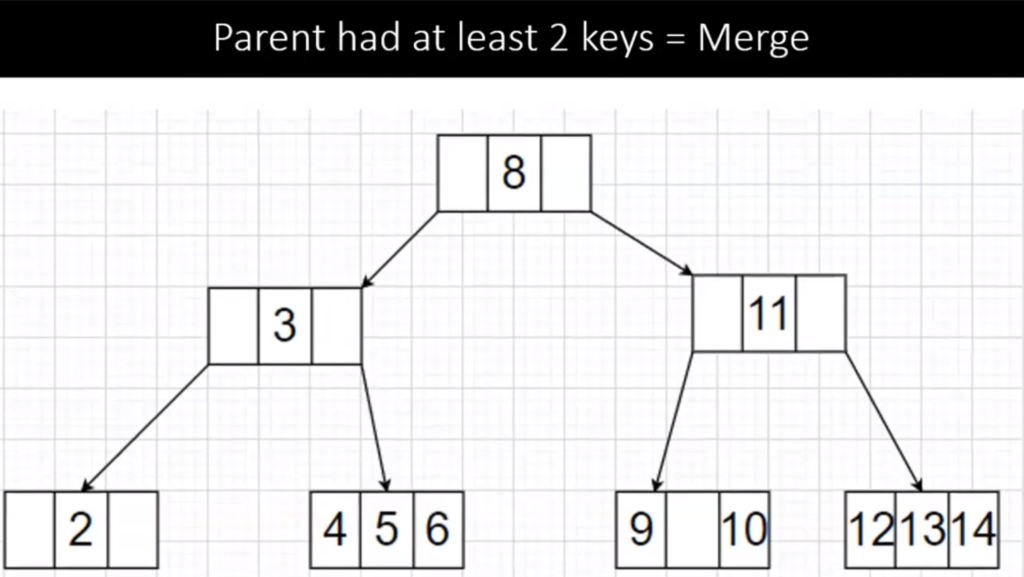
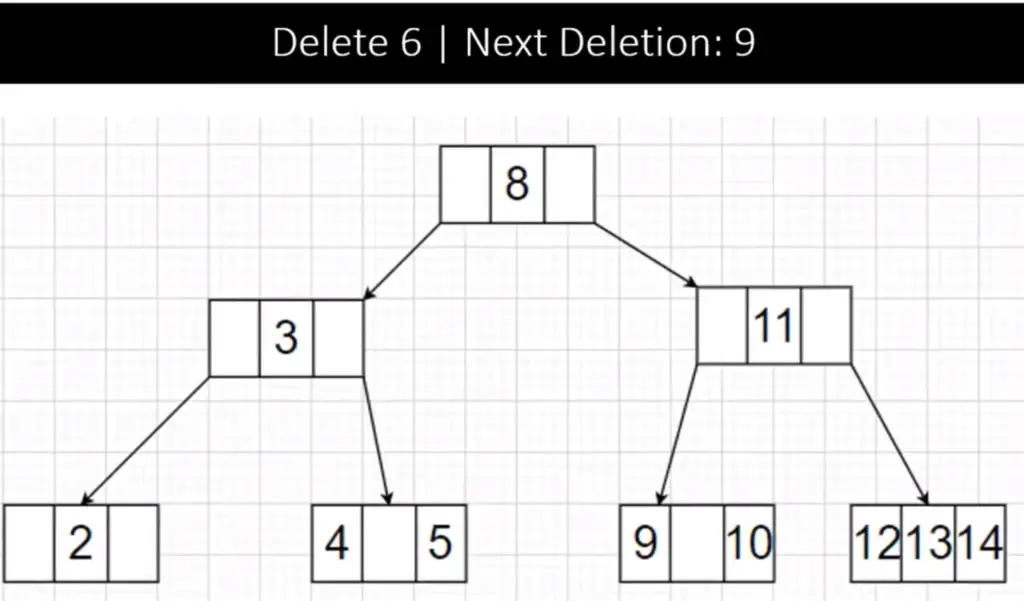
Step 4:
Now, To delete element 9 we traverse down to its node but on the way down since the child of node 8 have single keys so we merge them to a single node(3 8 11) to manage space effectively. Now, the node at 9 is a leaf node and has at least 2 keys (Case 1) so we delete it. The tree after the following operation is:
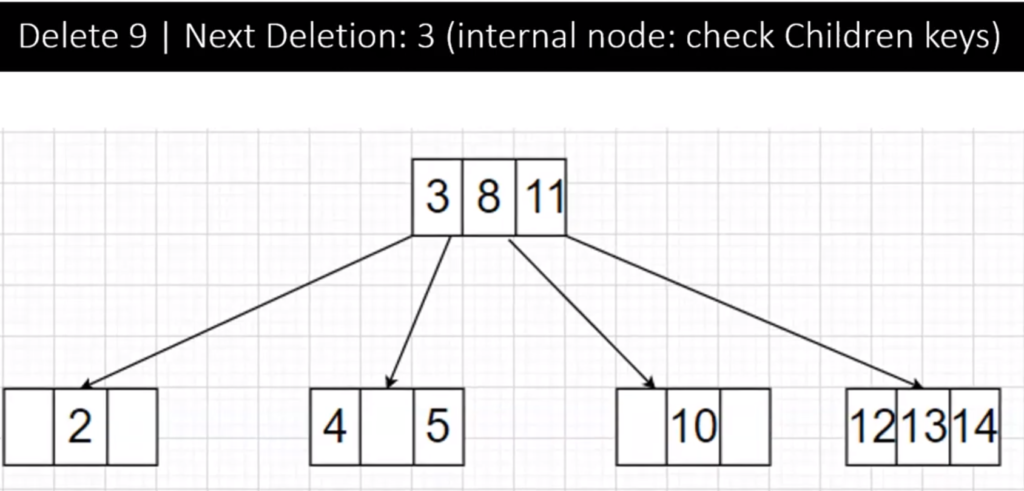
Step 5:
To delete 3, it is a Internal Node and its right child has 2 keys (4 and 5), this is Case 2 Type 2 so we replace 3 with its successor 4 then remove 4 from leaf node. After replacing and deleting 3 the 2-3-4 tree is :
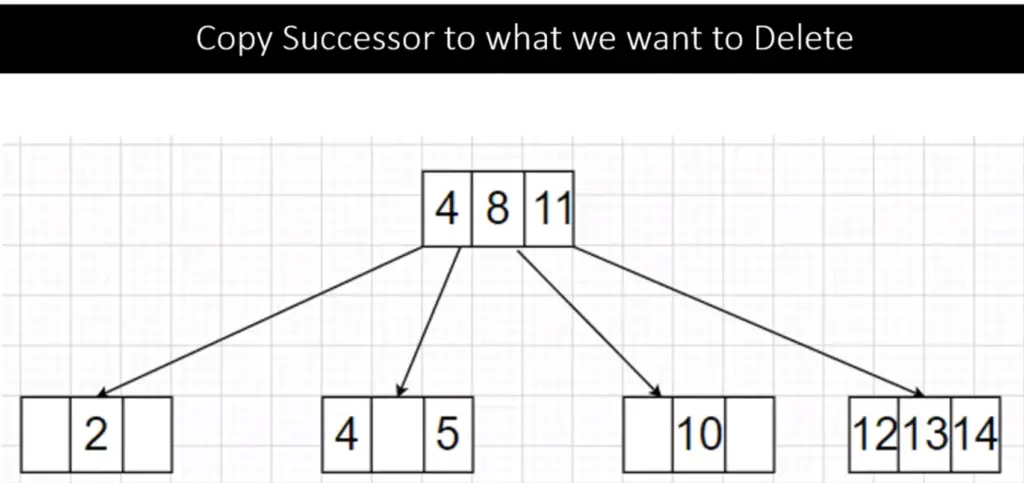
Step 6:
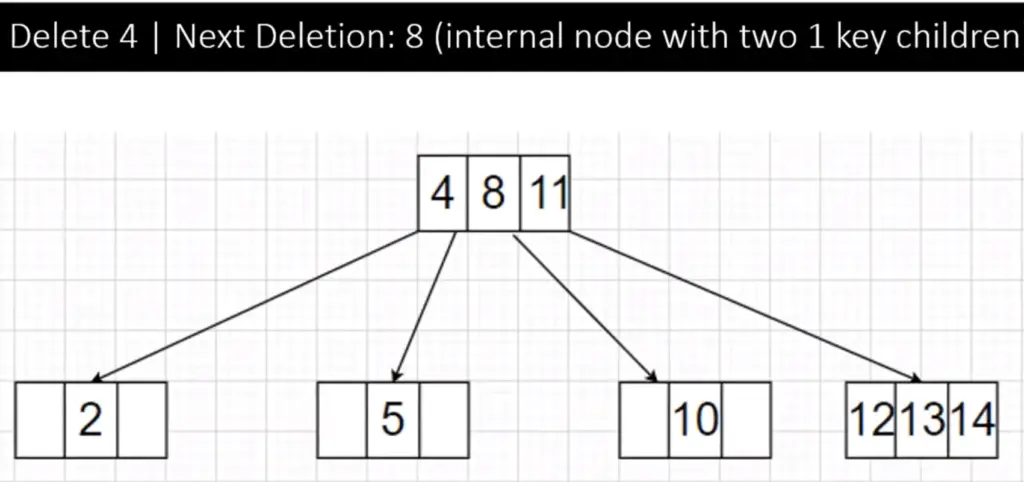
To delete 8, we see it is internal node with both child nodes having 1 key value: Case 2 Type 3, so we merge it with its child nodes then delete it the resultant 2-3-4 tree now after merging and deleting is shown below:
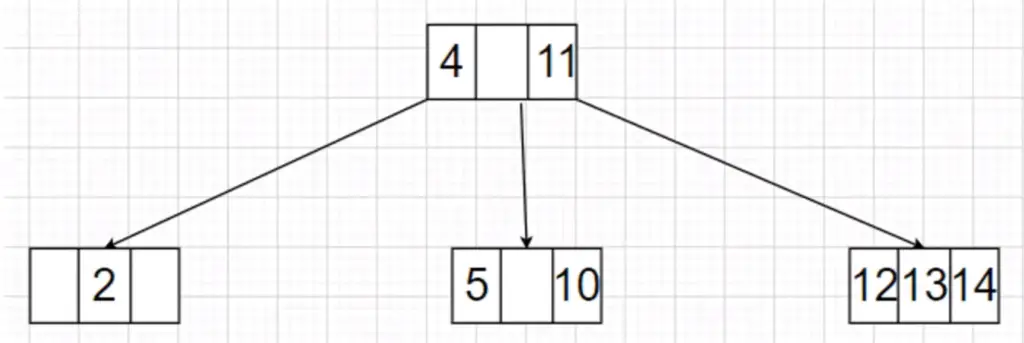
So here, we have seen examples of how to perform delete operations in 2-3-4 tree. You can try out more examples with the cases discussed above.
Time Complexity
- Insert Operation takes O(log N) as all splits and merges are just local transformations and we don’t need multiple passes on the tree.
- Deletion takes O(log N) considering rotation/merging are all O(1) operations.
Applications
- 2-3-4 Tree is a better choice for indexing and storing data in large and complex systems because of its efficient memory management and balancing nature.
- It is not widely used due to its complex structure and frequent change in structure on updating each node.
- 2-3-4 trees are mainly used to understand the concept behind Red-Black Trees as they are used more and its implementation is based on this.
So that’s it for the article you can try out the various operations discussed with different examples for clear idea. It is recommended to go through the cases carefully.
Feel free to leave your doubts/suggestions in the comment section below.
The post 2-3-4 Trees – Properties, Insertion, Deletion, Time Complexity & Applications appeared first on The Crazy Programmer.
from The Crazy Programmer https://ift.tt/2QST3VC