SQL Server database is a term you’re probably already familiar with. When it comes to storing large amounts of data, databases are extremely useful. And as you’ve figured out, SQL Server’s default settings aren’t always the best. When working with new user databases, this is the case. We can define a database as, In SQL Server, a database would be composed of a set of tables that store a particular set of structured data.
Introduction
SQL Server can be installed on a computer in one or more instances. Each SQL Server instance can have one or more databases.
Basically, a database table is made of rows, which are also called records or tuples, and columns, which are also called attributes. Every column in a table is made to hold a specific type of data, such as names, dates, and numbers. Every SQL Server database should have at least two operating system files: a data file and a log file. The information necessary to restore all transactions within the database is stored in log files. For allocation and management purposes, data files can indeed be clustered together in filegroups.
To improve I/O performance, SQL Server helps to create supplemental filegroups to disperse data and indexes across multiple discs. Today we are going to discuss these filegroups and when to use the multiple filegroups. Explore SQL Server Tutorial for more information.
What is Filegroup?
In a database, a filegroup is a rational approach for grouping objects. Filegroups should not be confused with actual files (.mdf, .ddf, .ndf, .ldf, etc.). Per database, you can even have multiple filegroups. All system tables will be stored in one filegroup, which will be the primary. Then you create more filegroups. You can set one filegroup as the default, and objects that aren’t assigned to a filegroup will be placed in it. You can just have multiple files in a filegroup.
- The primary data file is in this filegroup, as are any secondary files that aren’t in other filegroups.
- For administrative, data allocation, and placement purposes, user-defined filegroups could be formed to group data files together.
If we talk about an example- On three different disc drives, Data1.ndf, Data2.ndf, and Data3.ndf could be created and allotted to the filegroup fgroup1. The filegroup fgroup1 could then be used to create a table. The table’s data queries will also be scattered out across three discs, resulting in improved performance. A single file formed on a RAID (redundant array of independent discs) stripe set can achieve the same performance improvement. Files and filegroups, on the other hand, make it simple to add new files to new discs.
The following table lists the filegroups where all data files are stored.:
Primary: The primary file is contained in this filegroup. The primary filegroup contains all system tables.
Memory optimized data: The filestream filegroup is the foundation for a memory-optimized filegroup.
User defined: Any filegroup made by the user once the database is first created or later modified.
When to Create Filegroup?
- SQL Server accesses data using threads; each thread is responsible for retrieving or updating data on specific pages at specific locations on discs; if you have multiple filegroups and data is spread across the disc, SQL Server can take advantage of parallel threads, which improves database performance.
- If you’ve had a join operation that involves multiple tables in a database, putting them all in one filegroup will keep SQL Server running in parallel (for the most part); however, putting the tables in different filegroups and placing them on different discs or luns will increase operational efficiency against strongly accessed tables in different file groups because SQL Server can use parallel threads.
- While preparing or updating the database, your database performs poorly. Multiple threads can work together to retrieve data from different file groups at the same time.
- You have quite a table with several years of data, but you are only using a few recent years of data; that’s very helpful when partitioning the table and indexes. It also makes it easier to archive data and avoids unnecessary scanning of records that are not currently important.
- You have a large database, and full or disparity backup recovery times are unacceptable; if you discover database corruption of objects related to a specific filegroup, users could really restore just that file group to restore files quickly.
Learn more about SQL from this SQL Server Training to get ahead in your career.
How to Create Filegroup?
Method 1: Using T-SQL (Transact-SQL)
APPLY master GO SQLAge ALTER DATABASE FILEGROUP SQLAgeFG1 ADD GO
Method 2: Using Studio for Management
- Go to properties by right-clicking on the database you want to create a filegroup in.
- Select Filegroups from the drop-down menu.
- Select “Add” from the drop-down menu.
- Give the filegroup a suitable name and click OK.
Why Does one Need to Make Multiple Filegroups?
Effectiveness and recovery are the two main reasons for creating filegroups.
Disk performance issues can be alleviated by using filegroups that contain files created on specific discs. For example, your database might have one very large table with a lot of read and write activities, such as an orders table. You can make a filegroup, put a file in it, and then move a table to it by moving the clustered index. (I’ll show you how to do it later in this article.) You will get better performance if the file is created on a separate disc from other files. This is similar to the logic used in databases to separate data and log files. Once you spread files all over multiple discs, performance improves. Because instead of one person doing all the work, you have numerous heads reading and writing.
Filegroups can also be backed up and restored independently. In the event of a disaster, this could allow for faster object recovery. It can also aid in the management of large databases.
How to Create Multiple Filegroups?
The filegroups can be specified in the CREATE DATABASE statement when creating a new database.
We are going to make a database called FilegroupTest. PRIMARY and FGTestFG2 are the two filegroups. FGTest1 dat, which is assigned to PRIMARY, and FGTest2 dat, which is assigned to FGTestFG2.
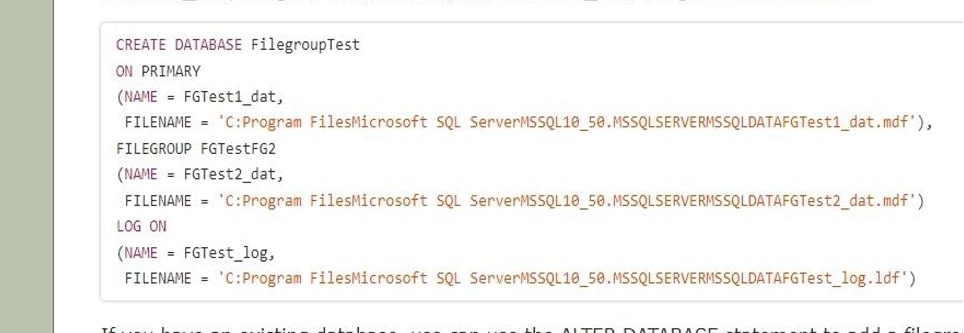
If you already have a database, you can add a filegroup with the ALTER DATABASE statement. FGTestFG3 will be added to FilegroupTest.

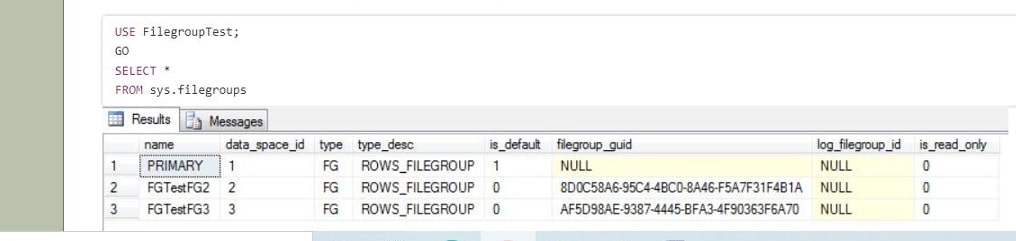
Using sys.filegroups, you can see the filegroups in a database.
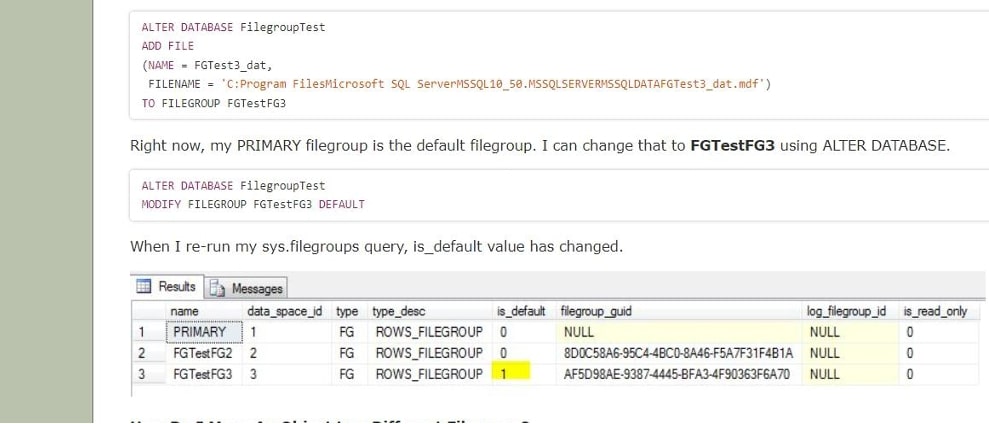
you can use ALTER DATABASE to create a new file, FGTest3 dat, and assign it to FGTestFG3.
Benefits of Using Multiple Filegroups
- You can take full advantage of the I/O bandwidth for every physical device/path to see you’ve positioned filegroups onto by splitting a database across multiple filegroups. Multiple filegroups on the same physical disc / LUN would provide no benefit, but multiple discs / LUNs can provide you with a multiple of the bandwidth of a single disc / LUN.
- You can go into great detail, storing parts of the database that are accessed less commonly on slower “nearline” media and maintaining the higher-activity pieces (heavily used indexes, tables, and so on) on the more expensive, faster storage.
- A decent indexing tactic can enable the ground states to grow while query times remain relatively constant. If you find that the I/O that hosts your filegroups is becoming saturated, you can improve performance by creating additional filegroups on additional discs / LUNs. Monitoring I/O performance is the key to determining if multiple filegroups will benefit you. If you’re CPU-bound or RAM-constrained, multiple filegroups won’t help you. I/O utilization is only one axis of comprehensive performance monitoring, and filegroups only help with that.
Conclusion
Filegroups are really a great way to manage your data while also improving performance and adding disaster recovery. It’s ideal if you can do this during the planning stages, but keep in mind that you can also add filegroups later. Piecemeal restore can be used to restore SQL Server databases with multiple filegroups in stages. The piecemeal restore actually does work in the same way as a standard restore, with three phases: data copy, redo and undo. Whereas your database and other filegroups continue to stay online, you can reinstate one of your filegroups. Please remember that your database ought to be offline when recovering the PRIMARY filegroup.
Author Bio:
I am Sai Priya Ravuri and I’m the content creator at MindMajix Technologies. I hold in-depth knowledge of Programming, Technologies, Business Intelligence, Analytics, Project Management and Methodologies, Business Process Management, Content Management systems, Enterprise Resource Planning, etc.
The post What is Filegroup in Sql Server? When & How to Create? appeared first on The Crazy Programmer.
from The Crazy Programmer https://ift.tt/bDUVBlr
Post a Comment