The key is unique for every lock. Similarly, those attributes which are unique for every entity in a single table, are known as key attributes. Keys are nothing else only the unique attributes associated with every entity.
Keys are useful in dbms for various reasons such as data integrity, efficient data retrieval, data consistency, data sorting, and many more. Let’s have a look at the different types of keys available in DBMS.
Candidate Key
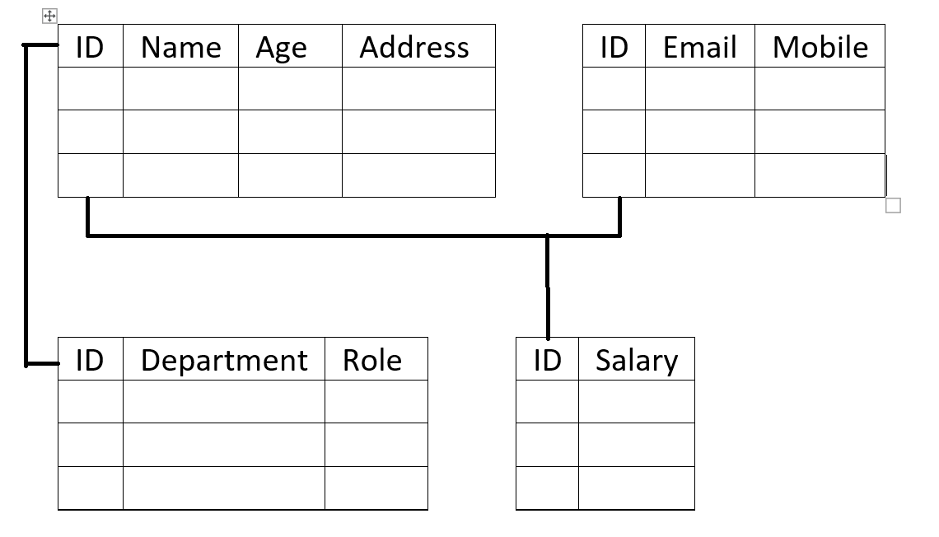
Those attributes which may be unique for an entity can be considered as Candidate keys. Like ID, name, mobile number, and address in the above table.
Primary Key
From candidate keys, we choose a key that is almost unique for every entity, called the Primary key for that entity and the whole table. Name, address, and mobile number may be not unique, but the ID number will be unique for every entity, so we choose the ID number as a primary key.
The primary keys should be easy to find, and allocate, and not be much complex.
Mobile numbers are also unique for every entity, but mobile number contains at least a 12-digit string, which is quite complex and lengthy for rapid use, so we can’t use it as a Primary key. Instead of this the ID number may be shorter and follow a fixed sequence, easy to generate and allocate, that’s why we should use the ID number as a Primary key.
Alternate Key
After selecting our primary key, the remaining candidate keys are considered as Alternate keys. Which may be used at the place of primary key in any specific situation.
Foreign Key
When we use the primary key to join tables, then we need to put the primary key in every table. In the main table, it is considered as a Primary key but in other tables, it is considered as a foreign key. Like in the above table “Employee”, the ID number is the Primary key, but if we use it in any other table of the database, then it is considered as a foreign key, and those other tables also have their own primary key as well. Primary key and foreign key concept is used to connect tables.
Composite Key
When we merge two or more candidate keys to create a more powerful or unique key for any entity or table then it is known as a composite key, but the primary key should be part of the composite key. Sometimes we can use any ordinary attribute to merge with a primary key to create a composite key.
Super Key
Sometimes only one primary key is not enough to maintain uniqueness for an entity, in that case, we merge the primary key with any one or more than one alternate key to create a module of the primary key, then this is known as a super key.
Like “ID + Email = Super key”.
In this case for every entity ID and Email both the attributes must be unique. If any one of them may not be unique then the entity will not be taken in the table.
Unique Key
Primary keys never accept NULL values. So, if we want to make any attribute a primary key with NULL values then this key will be called a Unique key. Most of the time Unique key is created by merging two or more alternate keys. In which the Primary key should not be null but the other alternate key may contain Null Value.
Like “ID + Email = Unique key”.
In this, the ID is a primary key and can allow a Null value, but the Email may hold a Null value.
NULL: This is a keyword, that shows the table that in this tuple or block no value is given, so at run time show this block as blank. We can’t leave any tuple or block blank, otherwise, the whole data set will be rejected, so in the blank place, we may put NULL.
The post 7 Different Types of Keys in DBMS appeared first on The Crazy Programmer.
from The Crazy Programmer https://ift.tt/TZ91EgX
Post a Comment