DIGITAL ELECTRONIC
In this article, we will look into an interesting problem asked in many coding interviews related to arrays: Dutch National Flag Problem. We will discuss the problem, the intuition behind it, and the application of the algorithm in certain scenarios. Along with this we will look at different approaches to solve the problem and analyze its complexities.
Dutch National Flag Problem is among the popular programming problems suggested by E. Dijkstra. So, from the name, it is clear that the problem is related to the Dutch or National Flag of the Netherlands. The flag of the Netherlands has three colors: Red, White and Blue in the same order. So the problem is if given a set of balls belonging to these colors we have to randomly arrange balls of red, white and blue such that balls of the same color are placed together and the order is maintained. In programming, we represent this problem as : Given an Array of 0’s, 1’s and 2’s we have to arrange them such that 0’s come before 1’s and 1’s come before 2’s. So we have to sort this array and arrange them in the order similar to Dutch National Flag.
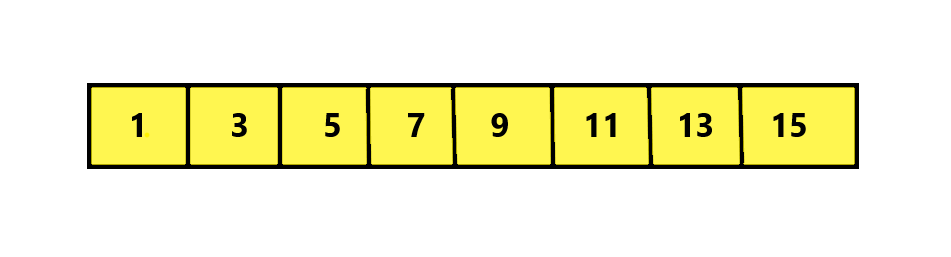
Let us understand this with an example. Consider this array:
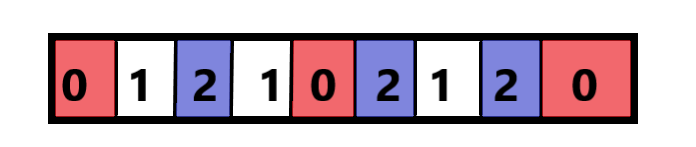
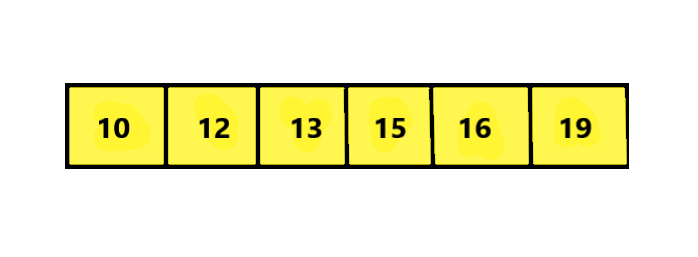
Also, consider the 0’s, 1’s and 2’s representing the colors Red, White and Blue of the flag. We have to sort this Array to look like this:

Now, let us discuss the Dutch National Flag Algorithm to do this but first also have a look at the other approaches before getting into the algorithm to get the idea of its necessity.
- Naïve Approach: The naïve approach will be to count the number of 0’s,1’s and 2’s in the array at first. Then we have filled the array serially with the occurrences of each number. This will require exactly 2 traversals of the array so we need to think of an approach requiring only 1 traversal.
Dutch National Flag Algorithm
Basically, the main idea of this algorithm is to move the 0’s to extreme left and 2’s to the right of the array respectively. Doing this, the 1’s automatically end up in the middle of the array. Thus, sorting the array at the end. The algorithm mainly consists of these steps:
- We maintain three pointers Low, Mid and High. At first we set, Low and Mid at start index (0) of the array respectively and the High pointer at end index (Size – 1) of the array.
- Then, we start iterating the array we take decisions based on Value at index Mid for each Arr[Mid] there are 3 cases.
-
- If Arr[Mid] = 0 : Then we Swap values at Arr[Low] with Arr[Mid] and increment both Low and Mid pointers.
- If Arr[Mid] = 1: Then we do nothing and just increment mid by 1. This ensures that all 1’s are in the middle..
- Or, If Arr[Mid] = 2: We Swap values at Arr[Mid] with Arr[High], then decrement the High Pointer to replace the value at high with value at mid.
-
- We repeat these steps considering the given conditions until Mid <= High.
Note: This Algorithm is only useful in sorting Arrays where Three-Way Partitioning can be applied.
Implementation in Java
public class DutchNationalFlag_Sample
{
// Swap values for case 0 and 2.
static void swap(int arr[],int i,int j)
{
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
static void sortArray(int arr[],int n)
{
int mid = 0;
int low = 0,high = n-1;
while(mid <= high)
{
switch(arr[mid])
{
case 0: swap(arr,low,mid);
low++; // we increment low and mid when we get 0
mid++;
break;
case 1: mid++; // we increment only mid to keep 1's in the middle.
break;
case 2: swap(arr,mid,high);
high--; //we decrement high as we moved 2 to last index or high.
break;
}
}
}
static void printArray(int arr[],int n)
{
for(int i=0;i<n;i++)
{
System.out.print(arr[i]+" ");
}
System.out.println();
}
public static void main(String args[])
{
int arr[] = { 0, 1, 2, 1, 0, 2, 1, 2, 0 };
int n = arr.length;
System.out.print("Array Before Sorting: ");
printArray(arr,n);
//Calling sort function.
sortArray(arr,n);
System.out.print("Array After Sorting: ");
printArray(arr,n);
}
}
Output:
Array Before Sorting: 0 1 2 1 0 2 1 2 0 Array After Sorting: 0 0 0 1 1 1 2 2 2
Time Complexity: We do a single traversal of the array, so the complexity will be O(n) moreover we do this in only one traversal.
Application
The Dutch National Flag Algorithm can be used in implementing Quicksort efficiently for inputs with majorly repeated elements. Quicksort exhibits its worst-case performance in such inputs taking O(n2) time. The Dutch National Flag Algorithm with its 3-Way Partitioning method can help resolve the partition routine separating the values into three groups:
- The values less than the pivot,
- The values equal to the pivot,
- And, the values are greater than the pivot.
The values equal to the pivot are already sorted, so only the value less than or greater than the pivot needs to be recursively sorted. This linear-time partition routine is similar to 3–way partitioning for the Dutch national flag problem. This will make Quicksort work efficiently in O(n) time for inputs having identical values.
Let us have a quick look at the Pseudocode for the Partition routine using DNF Algorithm.
partition(arr[],start,end)
{
mid = start;
pivot = arr[end];
while (mid <= end)
{
if (arr[mid] < pivot)
{
swap(arr[start], arr[mid]);
++start, ++mid;
}
else if (arr[mid] > pivot)
{
swap(arr[mid], arr[end]);
--end;
}
else
{
++mid;
}
}
// mid contains the position of partition.
return mid;
}
So, That’s it for the article you can try out the code with different examples and execute them for a clear idea. Feel free to leave your doubts/suggestions in the comment section below.
The post Dutch National Flag Problem appeared first on The Crazy Programmer.
from The Crazy Programmer https://ift.tt/3fxTP4b